当AI开始自己“动手”:Agent安全,为什么成了2026年最危险也最重要的话题

AI Agent 正在重新定义安全的边界
本文导语:当AI 从“会说”走向“会做”,安全问题也从内容风险升级成了行动风险。从提示注入、权限失控到“数字员工”治理,AI Agent 安全正在重写企业防线。 |
过去两年,大家讨论大模型安全,最常提的问题是:它会不会“胡说八道”?会不会泄露隐私?会不会生成不该生成的内容?
但到了今天,行业真正开始警惕的,已经不是一个模型说错一句话,而是一个Agent 做错一件事。
因为它不再只是回答问题。它开始会打开网页、调用工具、读写文档、连数据库、发邮件、跑流程,甚至直接替人执行任务。
一旦风险发生,后果也不再只是“答非所问”,而可能是:
•一笔错误付款
•一封错误邮件
•一次越权访问
•一条敏感数据外发
•一整串自动化流程被带偏
这就是为什么,2025 到 2026 年,AI Agent 安全突然从一个技术圈里的分支议题,变成了整个行业都在加速补课的核心课题。
一句话概括:当AI 从“会说”走向“会做”,安全问题也从内容风险升级成了行动风险。 |
一、Agent 时代,真正可怕的不是“胡说”,而是“误操作”和“被劫持”
过去大家担心的是模型答错。现在大家更担心的是:它明明没有答错,但却做错了。
这两者的区别非常大。传统聊天模型的风险,很多时候停留在输出层。而Agent 的风险,已经深入到了执行层。
比如,一个接了日历、邮件、知识库和内部系统的Agent,如果被误导,它可能不是“回答错误”,而是:
•把不该发的内容发给了外部人员
•把内部文档读给了无权限用户
•在错误前提下调用高权限工具
•被恶意网页或文档“带节奏”,执行了一连串本不该执行的动作。
这意味着,安全问题的重心已经变了。以前是在防“坏内容”;现在是在防“坏动作”。
传统AI 安全 • 输入过滤 • 输出审核 • 内容合规 • 防止“说错话” | Agent 安全 • 权限控制 • 行为审计 • 工具隔离 • 防止“做错事” |
以前像是给AI 戴一个“嘴套”;现在更像是要给它装上一整套刹车、限速器、方向盘和行车记录仪。
二、Prompt Injection:Agent 时代的“指挥权争夺战”
如果说最近两年Agent 安全领域最重要的共识之一,那就是:
Prompt Injection 不是一个提示词技巧问题,而是一个控制权问题。 |
很多人第一次听到“提示注入”,会以为这只是有人故意让模型“别听前面的话”。但在Agent 场景里,这件事远比想象中严重。
因为一个Agent 不只是和用户对话。它还会读网页、读文档、读邮件、读知识库、读工具返回结果。于是,攻击者根本不需要直接对它说话。
他只要把恶意指令藏进:
•一个网页
•一封邮件
•一份PDF
•一段文档
•一个知识库页面
•甚至一张图、一个界面元素
就有可能让Agent 把这些内容,误认为是更值得遵守的“命令”。

Agent 最大的风险之一,不再是“有没有理解你”,而是“它到底在听谁的话”。
三、防线正在从“模型层”转向“系统层”和“协议层”
很多团队刚开始做AI 安全时,思路还比较简单:输入做一层过滤,输出做一层审核,在系统提示词里多写几句“不要做什么”。
但到了Agent 时代,这种思路很快就不够了。因为真正危险的地方,不只是模型本身,而是模型和外部世界之间的连接点。
Agent 安全不能只靠“让模型更聪明”来解决,更要靠“让系统更克制”来解决。 |
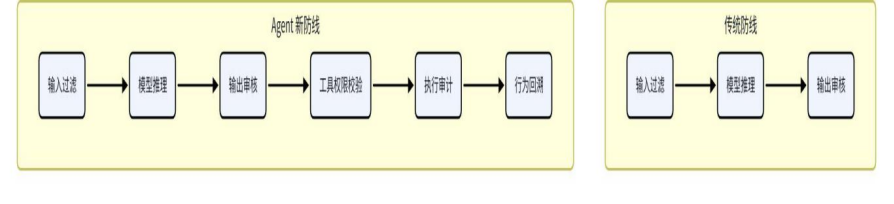
真正有效的安全,不是寄希望于Agent 永远不被诱导,而是即便它被诱导了,也只能撞上一层又一层权限边界,没法一路滑到高危动作。
四、MCP 火了,“万能接口”也把安全问题一起带火了
最近AI Agent 圈子里,一个很热的词是 MCP(Model Context Protocol)。它正在成为 Agent 连接外部工具和数据源的一种通用方式,像是给 AI 世界装上了“统一接口”。
接口越通用,风险面越大。一个设计不严谨的MCP Server,可能带来几类典型问题:
风险类型 | 具体表现 |
越权访问 | Agent 拿着用户权限访问了本不该访问的资源 |
链式风险 | 一个低风险工具调用,链式触发成高风险动作 |
结果污染 | 返回结果未经隔离与校验,反过来继续污染Agent 判断 |
注入入口 | 外部系统被当作“可信来源”,实际却可能成为注入入口 |
真正危险的,不是Agent 会不会调用工具,而是它在什么边界内调用工具。
五、Agent 安全终于开始“工程化”了
以前不少团队做AI 安全,有点像“玄学防御”——加几条 system prompt,写几条禁止规则,跑几个测试样例,然后希望它上线后“别出大事”。
但最近一年的变化很明显:Agent 安全正在从“经验主义”,走向“工程化治理”。
企业不再只问“模型听不听话”,而开始问:
•它到底读了哪些输入?
•它在哪一步被带偏了?
•它调用了哪些工具?
•它为什么做出这个决策?
•整条执行链能不能回放?
•出了问题能不能追责、回滚和修复?
安全的本质,从来不是“相信它不会犯错”,而是“它犯错时你能不能看见、定位、处理”。 真正成熟的Agent 安全能力,不是一个“拦截器”,而是一整套运行时治理体系。 |
六、把Agent 当“数字员工”管理,而不是当“高级聊天框”管理
这是最重要、也最值得写进所有企业决策层脑海里的一个变化:Agent 的治理逻辑,正在从模型治理,转向身份治理。
因为一个真正进入企业流程的Agent,越来越像一个“数字员工”——它有角色、有权限、有职责范围、有操作边界。

Agent 正在成为企业中的新员工
既然如此,企业对人的那套治理逻辑,就必须逐步迁移到Agent 身上:
必须回答的问题 • 它是谁? • 它代表谁? • 它能做什么? • 它不能做什么? • 它的权限从哪里来? | 必须具备的能力 • 它做过什么(行为留痕) • 每一步是否可追踪 • 出错时谁来兜底 • 能否回滚和修复 • 能否审计和追责 |
如果一个Agent 没有身份、没有授权边界、没有行为留痕,却能自由读写企业系统,那本质上就相当于一个没有工牌、没有权限清单、没有审批流程、还能四处开门的“隐形员工”。
未来真正成熟的企业级Agent,一定不是“最能干”的那个先赢,而是“最可控”的那个先落地。
七、Agent 安全的底层逻辑:全面走向零信任化

把最近一波安全进展浓缩成一句话:Agent 安全,正在全面走向零信任化。
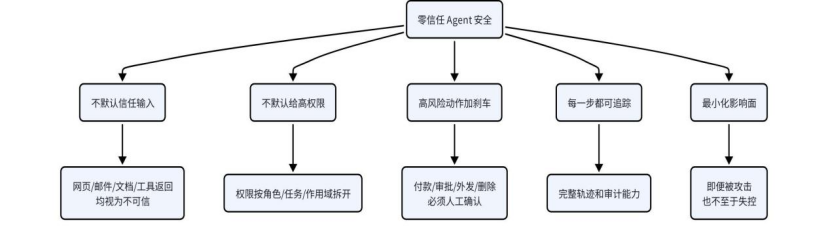
零信任五原则:
1.不默认信任输入 —— 用户输入、网页内容、邮件正文、文档内容、第三方工具返回结果,都不一定可信;
2.不默认给高权限 —— 权限必须按角色、按任务、按作用域拆开
3.高风险动作必须加“刹车” —— 涉及付款、审批、外发、删除、账号操作等动作时,该人工确认就必须人工确认;
4.每一步都要可追踪 —— 为了在系统越来越复杂时,仍然知道问题出在哪;
5.防不住全部注入,就把影响面降到最小 —— 与其幻想“绝不被攻击”,不如先做到“即便被攻击,也不至于失控”。
八、2026 年,Agent 安全真正改变的,不只是技术,而是产品思维
过去很多团队做Agent,最爱问的是:“它还能做什么?” 而今天,一个更成熟的问题是:“它绝对不能做什么?” |
这两个问题的差别,决定了产品最终能不能进入真实世界。
未来的竞争,不再只是“大模型能力竞赛”,而会越来越变成:
•谁更能控制权限
•谁更能隔离风险
•谁更能追踪行为
•谁更能解释决策
•谁更能让企业放心接入核心系统
Agent 的商业化上限,正在被安全能力重新定义。 一个不能治理的Agent,再聪明,也只能停留在演示环节;一个可约束、可审计、可回滚的 Agent,哪怕没那么炫,反而更可能真的被部署到生产环境里。 |
九、写在最后:AI Agent 的“成人礼”,不是更强,而是更可控
如果把这轮AI Agent 安全防护进展放到更长的时间线上看,你会发现一件很有意思的事:
过去,行业最兴奋的是Agent 终于开始“会做事”;而现在,行业最清醒的部分,正在讨论如何让它“做事但不失控”。
这其实是一种成熟。
当AI 开始替人登录系统、发送信息、调取数据、执行流程时,我们真正要回答的问题,就已经不再是“它能不能做?”,而是:
“它该在什么规则下做?”“它做到哪一步必须停?”“谁给它授权?”“它出了问题谁来负责?”
一个真正有用的Agent,首先必须是一个被约束得足够好的 Agent。 这不是保守。恰恰相反,这才是AI Agent 走向大规模应用之前,最关键的一次“成人礼”。 |